- folium MarkerCluster : 지도 확대 정도에따라 마커 표시를 그룹으로 출력

from folium.plugins import MarkerCluster
library_map = folium.Map(location = [37.55, 126.98], zoom_start = 12)
mc = MarkerCluster()
for idx, row in df.iterrows() :
mc.add_child(
folium.Marker(location = [row['위도'],row['경도']],
popup = row['시설구분'],
tooltip = row['시설명']
)
)
library_map.add_child(mc)
library_map.save('library3.html')
- iterrow() : 한 행을 리스트 형태로 반환, 반복문에서 사용 시 인덱스와 레코드 값을 리턴
- 경기도 인구 지도 시각화 ( 경기도 행정구역 경계 json)
# 경기도의 인구데이터와 위치 정보를 이용하여 지도에 인구 표시
import json
df = pd.read_excel('data/경기도인구데이터.xlsx', index_col = '구분')
df.info()
# 1. 컬럼의 자료형을 문자열형으로 변경
df.columns = df.columns.map(str)
df.columns
# 2. 위치정보 데이터 읽기
geo_data = json.load\
(open('data/경기도행정구역경계.json', encoding = 'utf-8'))
type(geo_data)
# 3. 지도에 표시하기
g_map = folium.Map(location = [37.55, 126.98], zoom_start = 9)
year = '2017'
folium.Choropleth(geo_data = geo_data, # 위치 정보를 가진 dict 데이터
data = df[year],
columns = [df.index, df[year]],
fill_color = 'YlOrRd',
fill_opacity = 0.7,
line_opacity = 0.3,
# ↓색상으로 표시될 데이터의 범위 지정
threshold_scale = [10000,100000,200000,300000,400000,500000,600000,700000],
key_on = 'feature.properties.name', # 데이터와 지도표시될 지역부분 연결 값 설정
).add_to(g_map) # json파일 접근 경로, 참조 경로
g_map.save('경기1_'+year+'.html') # json파일의 name과 데이터의 구분명이 같아야 연동됨
- 미국 실업율 지도 시각화
state_geo = 'data/us-states.json' # 파일 위치정보를 가진 문자열, json.load(open)안함
state_unemployment = 'data/US_Unemployment_Oct2012.csv'
state_data = pd.read_csv(state_unemployment) # 지도에 표시할 실업율 데이터
m = folium.Map(location = [48,-102], zoom_start = 3) # 미국지도
folium.Choropleth(
state_geo, # json 파일 위치. 알아서 읽어옴
data = state_data,
columns=['State','Unemployment'],
key_on = 'feature.id', # 데이터와 지도 연결
fill_color = 'YlGn',
fill_opacity = 0.7,
line_opacity = 0.2,
legend_name = 'Unemployment Rate (%)', # 범례
).add_to(m)
m.save('usa1.html')
Numpy
- 행렬, 통계 관련 기본 함수, 배열 기능을 제공하는 모듈
- 주요 속성
| 속성 | 설명 |
| ndarray.ndim | 배열의 차원(축) 수 |
| ndarray.shape | 배열의 차원 각 차원에서 배열의 크기를 나타내는 정수의 튜플 매트릭스와 n개의 행과 m개의 열 (n,m).shape 따라서 튜플의 길이는 축의 수 |
| ndarray.size | 배열의 요소 수 |
| ndarray.dtype | 요소의 유형 |
| ndarray.itemsize | 각 요소의 크기(바이트) |
| ndarray.data | 배열의 실제 요소를 포함하는 버퍼 |
- 배열 생성
| array | 리스트 , 튜플에서 배열 생성 가능 |
| zeros | 0.0으로 이루어진 배열 생성 |
| ones | 1.0으로 이루어진 배열 생성. (정수 생성 옵션 dtype=int) |
| arange | 범위까지의 일련의 숫자 배열 생성. 1차원 배열 |
| linspace | 범위 내의 숫자를 균일한 간격으로 배열 생성 |
| reshape | 원하는 배열로 재생성. 배열 생성을 위한 요소의 개수가 맞아야한다. |
| nonzero | 배열중 0이 아닌 요소의 위치값 반환 |
| random.normal | (평균,표준편차,개수) : 정규분포 형태의 난수 생성 |
| random.choice | 범위 내 난수 생성 (중복허용 옵션 replace=True ) |
| random. random | 난수 발생 |
| random.randint | 정수형 난수 리턴 |
| random.default_rng(1) | seed값 설정 |
- 행/열 기준 합치기, 나누기
- vstack(): 행 기준으로 합치기. 열의 개 수가 같아야함
- vsplit () : 행 기준으로 나누기
- hstack(): 열 기준으로 합치기. 행의 개수가 같아야함
- hsplit() : 열 기준으로 나누기
- 통계함수
| max(axis=1) | 행 중 최대값 |
| max(axis=0) | 열 중 최대값 |
| cumsum(axis=1) | 행의 누적 합계 |
| cumsum(axis=0) | 열의 누적 합계 |
| argmax(axis=1) argmin(axis=1) |
행 중 최대값/최소값의 인덱스 |
| argmax(axis=0) argmin(axis=0) |
열 중 최대값/최소값의 인덱스 |
- 그 외 함수
| flat | 배열의 요소들만 리턴 |
| floor | 작은 근사 정수 |
| ceil | 큰 근사 정수 |
| ravel | 1차원 배열로 변경 |
| resize | 배열 객체 자체를 변경 |
- 배열의 모든 요소를 100으로 변경하기
k = np.random.randint(10,size=(2,12))
k[:] = 100
k[:,:] = 100
# 한개 행의 요소값이 100값을 저장
k[0,:]= 100
# 한개의 값에 100값을 저장
k[0,0] = 100
- 단위 행렬: 대각선(행==열) 셀의 값이 1인 배열
n = np.eye(10,10)
n
#결과
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])
데이터 전처리 및 시각화 실습
: 지정한 동과 비슷한 인구 구조 비율을 가지고 있는 동 찾기
df = pd.read_csv('data/age.csv', encoding = 'cp949', thousands = ',', index_col=0)
# 컬럼명 변경하기
col_name = ['총인구수','연령구간인구수']
for i in range(0,101) :
col_name.append(str(i)+'세')
df.columns = col_name
df.columns
# 인구 구조 비율. 모든 컬럼의 값을 총인구수로 나누기
df = df.div(df['총인구수'], axis = 0)
# 데이터값이 커서 그래프 그리기에 부적합한 컬럼 삭제
del df['총인구수'], df['연령구간인구수']
# 지정동 = 역삼2동 . 인구 구조 비율 그래프 그리기
name = '역삼2동'
a = df.index.str.contains(name)
df2 = df[a]
df2
# df2.index에서 행정동 코드 제거 (인덱스 지저분해서 정리)
names = list(df2.index)
names[0]= names[0][:names[0].find('(')]
df2.index = names
df2.index
# 행렬 치환해서 그래프
df2.T.plot()
# 비슷한 인구 구조 비율을 가진 동 찾기
# 역삼2동을 제외한 다른 데이터를 저장한 df3 생성
b = list(map(lambda x :not x, a))
df3 = df[b]
mn = 1 # 오차 최대값 초기화.(1을 넘을수없다.)
for label,content in df3.T.items() :
s = sum((content - df2.iloc[0])**2) # 현재레코드와 df2 데이터의 오차값의 합
if s < mn : # 최종적으로 가장 작은 오차값이 담긴다.
mn = s;
result = content
name = result.name
result.name = name[:name.find('(')]
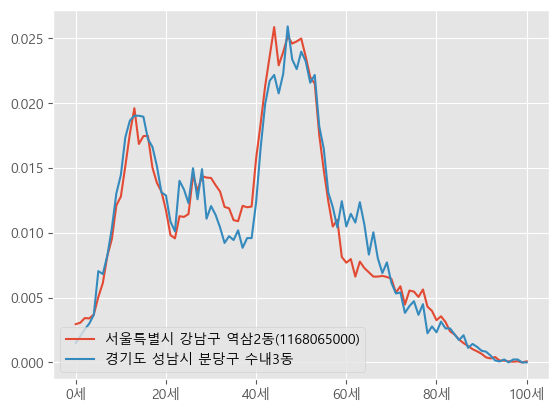
df2.T.plot() # 역삼2동 데이터
result.plot() # df2 데이터와 오차값이 가장 적은 데이터
plt.legend() # 범례 출력
진도가 빠른거같은데 기분탓일까
프로젝트 얘기는 갑자기 왜 ... 과제 평가 아니었나요 헝헝
왜 프로젝트 기간 일주일이나 잡으시는거죠 헝헝헝
'환경, 에너지' 카테고리의 다른 글
| [EMS] 데이터 전처리 및 시각화 실습 (0) | 2024.07.11 |
|---|---|
| [EMS]BeautifulSoup, Selenium (0) | 2024.07.10 |
| [EMS] matplotlib, folium (0) | 2024.07.08 |
| [EMS] Pandas 기본 (0) | 2024.07.03 |
| [EMS] Python 예외처리, 클래스와 모듈, 정규식 (1) | 2024.07.03 |



